
pandas 의 한계
Dataset을 불러올 때 pandas 의 DataFrame 객체를 불러와서 분석하는 것이 일반적이다.
그래서 나 역시 pandas 로 분석을 하곤 했었다.
하지만 Dataset의 크기가 굉장히 많을 경우, pandas 만으로는 한계가 있다.
pandas 의 DataFrame 은 In-Memory 기반이기에 메모리 한계가 있다.
그래서 불러온 Dataset의 특정 column 에 대한 dtype 을 변환하거나
(이를테면 object 타입을 category 로 변환을 한다거나, 64bit 숫자 타입을 32bit로 변환한다거나)
혹은 resampling을 한다거나 여러 방법론이 존재한다.
이러한 눈물 나는 노력에도 불구하고 Dataset이 GB 급만 되더라도 엄청나게 메모리를 많이 잡아먹는다.
일반적으로, 빅데이터라고 한다면 최소 TB 급 이상은 되는 경우들이 많다.
그런데 GB 급만 되어도 메모리를 상당히 많이 잡아먹고 있어서 실질적으로 분석하는데 한계가 있다.
설령, 이토록 방대한 데이터를 메모리에 올려놓았다고 해도, 느려터진 연산 속도가 발목을 잡는 경우가 잦다.
pandas 에는 이러한 한계점들이 존재하기 때문에 여러 가지 데이터 분석 패키지들을 사용해 봤다.
1. vaex

vaex 는 Lazy Out-of-Core DataFrames이며, pandas 와 유사한 파이썬 라이브러리이다.
특징은 큰 Table 형식의 Dataset을 시각화하고 탐색한다.
최대 10억 개 까지 N차원 그리드에서 평균, 합계, 개수, 표준 편차 등의 통계를 계산할 수 있다. (초당 10^9 개의 객체 및 행)
시각화는 히스토그램, 밀도 플롯 및 3D 볼륨 렌더링을 사용하여 수행되므로 빅데이터의 대화형 탐색이 가능하다.
vaex 는 최상의 성능(메모리 낭비 없음)을 위해 메모리 매핑, 제로 메모리 복사 정책 및 지연 계산을 사용한다.
이와 같은 이유로, 처음에는 vaex 를 사용하고자 했으나, 사용 중인 회사 서버 PC에 GPU가 없었기에 사용하지 않았다.
이후, 서버 PC에 GPU를 내장해서 vaex 도 같이 사용하고 있다.
(사실, 내장된 GPU가 워낙 오래된 모델이라 성능 향상은 거의 없는 거나 마찬가지긴 하지만 말이다...)
2. dask

dask 는 병렬 및 분산 컴퓨팅을 위한 Python 라이브러리이며, 사용 및 설정이 쉽다.
또한, 확장성을 제공하고 복잡한 알고리즘의 lock을 해제하는 데 강력하다.
다만, 나의 경우에는 Machine Learning을 통한 Model Training을 진행해야 하기 때문에 Dataset을 따로 compute 해야 했다.
이 과정에서 Dataset은 pandas 의 DataFrame 객체로 메모리에 모조리 올라가 버리는데,
이렇다 보니, 결국 메모리 부하가 되어 문제가 발생했었다.
3. Apache Spark

Apache Spark는 단일 노드 머신이나 클러스터에서 데이터 엔지니어링, 데이터 과학, 머신 러닝을 실행하기 위한 다국어 엔진이다.
주요 특징들은 다음과 같다.
3.1. Batch/streaming data
Python, SQL, Scala, Java 또는 R 등 선호하는 언어를 사용하여 일괄 처리 및 실시간 스트리밍으로 데이터 처리를 통합할 수 있다.
3.2. SQL analytics
대시보드 및 임시 보고를 위한 빠르고 분산된 ANSI SQL 쿼리를 실행한다. 대부분의 데이터 웨어하우스보다 빠르게 실행된다.
3.3. Data science at scale
다운샘플링에 의존하지 않고도 페타바이트 규모의 데이터에 대한 탐색적 데이터 분석(EDA)을 수행한다.
3.4. Machine Learning
노트북에서 머신 러닝 알고리즘을 훈련하고 동일한 코드를 사용해 수천 대의 머신으로 구성된 내결함성 클러스터로 확장한다.
3.5. PySpark
PySpark는 Apache Spark용 Python API이다.
Python을 사용하여 분산 환경에서 실시간 대규모 데이터 처리를 수행할 수 있다.
또한 데이터를 대화형으로 분석하기 위한 PySpark Shell도 제공한다.
PySpark는 Apache Spark와 결합하여 모든 규모의 데이터를 처리하고 분석할 수 있도록 해준다.
PySpark는 Spark SQL, DataFrames, 구조적 스트리밍, 머신 러닝(MLlib), Spark Core 등 Spark의 모든 기능을 지원한다.
4. polars
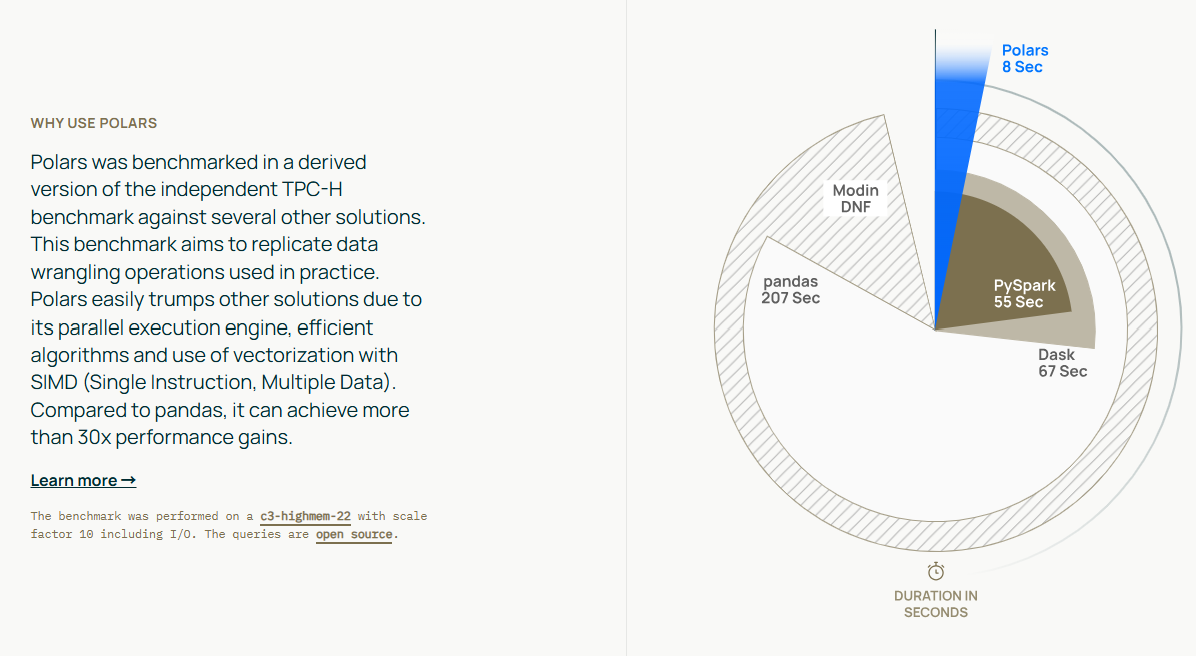
polars 는 데이터 조작을 위한 오픈소스 라이브러리로, 단일 머신에서 가장 빠른 데이터 처리 솔루션 중 하나로 알려져 있다.
표현력이 뛰어나고 사용하기 쉬운 잘 구조화되고 형식화된 API를 특징으로 한다.
polars 는 처음부터 성능을 염두에 두고 개발되었다.
멀티스레드 쿼리 엔진은 Rust로 구현되어 있으며, 효과적인 병렬 처리를 위해 설계되었다.
벡터화 및 컬럼 처리로 캐시 일관성 있는 알고리즘과 최신 프로세서에서 높은 성능이 가능하다.
정리
방대한 양의 데이터를 분석하거나 연산할 때, pandas의 DataFrame 만으로는 한계가 있었다.
때문에 현재는 Apache Spark와 dask 및 polars 의 적절한 조합으로 사용하고 있다.
처음에 Dataset을 불러올 때, 분산 처리해서 dask의 DataFrame 객체로 불러온다.
상당히 많은 연산을 진행시켜야 하는 경우에는 polars의 DataFrame으로 불러와서 연산을 하고 있다.
GPU 내장 이후에는 vaex도 적절히 사용 중이다.
'찐따의 프로그래밍 독학 > 찐따의 파이썬 독학' 카테고리의 다른 글
| 찐따의 파이썬 독학 - pyenv virtualenv로 가상 환경 사용 하기 (1) | 2025.03.07 |
|---|---|
| 찐따의 파이썬 독학 - pyenv 프로젝트 단위 가상 환경 관리 (1) | 2025.03.06 |
| 찐따의 파이썬 독학 - 흔한 찐따의 논문 검색엔진(Journal Search-Engine) 개발 및 테스트 (0) | 2022.09.04 |
| 찐따의 파이썬 독학 - 흔한 찐따의 양자 시뮬레이터(Quantum Simulator) 개발 및 테스트 (0) | 2022.09.03 |
| 찐따의 파이썬 독학 - Astropy를 활용한 천문학 데이터 FITS 영상 처리 (1) | 2022.07.29 |